Bloomfilter sind wie die Türsteher der Datenwelt – sie sagen dir schnell, ob etwas wahrscheinlich im Club (deinem Datensatz) ist oder definitiv nicht, ohne tatsächlich die Türen zu öffnen. Diese probabilistische Datenstruktur kann unnötige Suchvorgänge und Netzwerkaufrufe erheblich reduzieren, wodurch dein System schneller und effizienter wird.
Die Magie hinter dem Vorhang
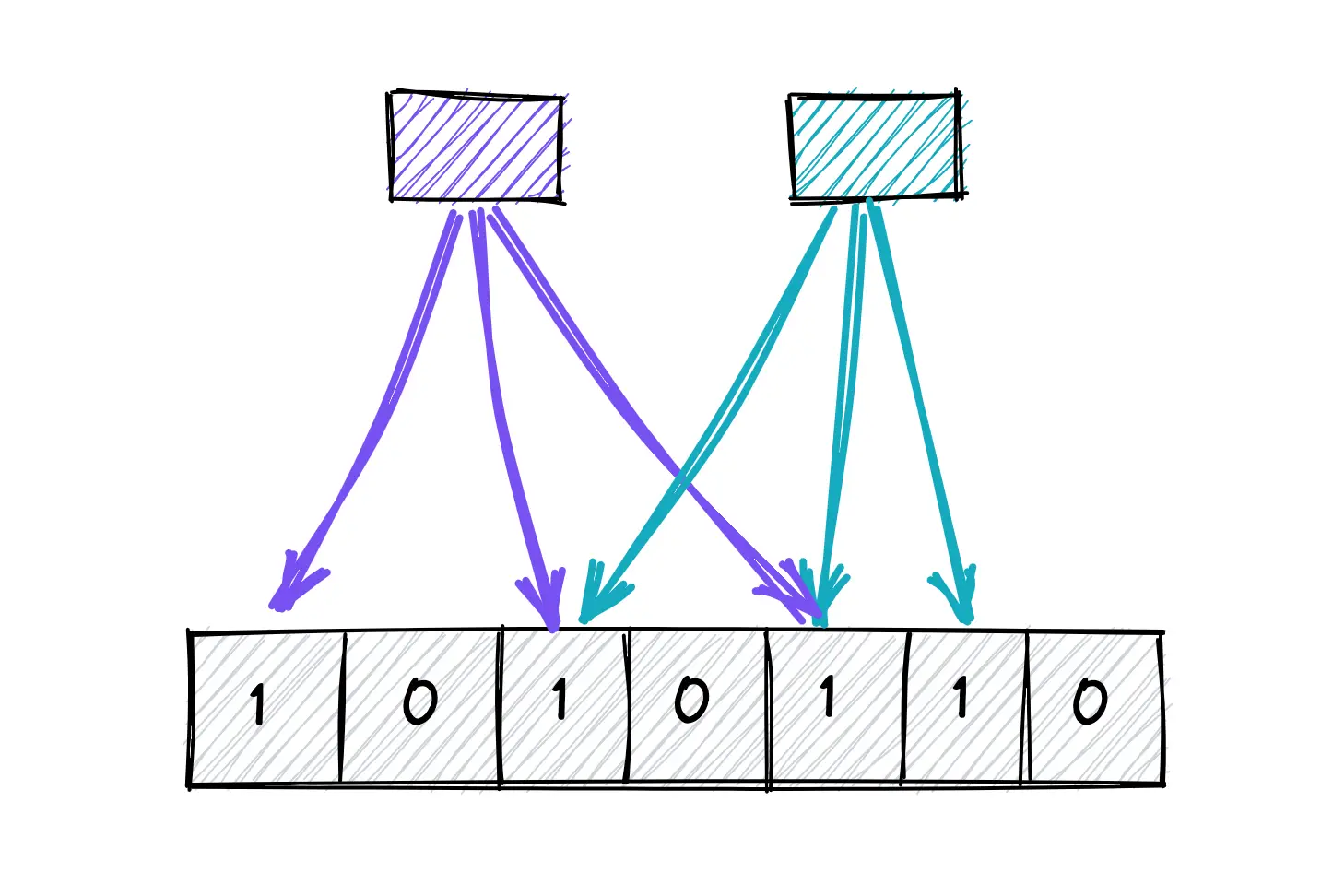
Im Kern ist ein Bloomfilter ein Array von Bits. Wenn du ein Element hinzufügst, wird es mehrfach gehasht, und die entsprechenden Bits werden auf 1 gesetzt. Um zu überprüfen, ob ein Element existiert, wird es erneut gehasht und überprüft, ob alle entsprechenden Bits gesetzt sind. Es ist einfach, aber mächtig.
class BloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.bit_array = [0] * size
def add(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
self.bit_array[index] = 1
def check(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
if self.bit_array[index] == 0:
return False
return True
Praktische Anwendungen: Wo Bloomfilter glänzen
Schauen wir uns einige praktische Szenarien an, in denen Bloomfilter den Tag retten können:
1. Caching-Systeme: Der Türsteher
Stell dir vor, du betreibst ein groß angelegtes Caching-System. Bevor du auf den teuren Backend-Speicher zugreifst, kannst du einen Bloomfilter verwenden, um zu überprüfen, ob der Schlüssel möglicherweise im Cache existiert.
def get_item(key):
if not bloom_filter.check(key):
return None # Definitiv nicht im Cache
# Möglicherweise im Cache, lass uns nachsehen
return actual_cache.get(key)
Diese einfache Überprüfung kann Cache-Fehlzugriffe und unnötige Backend-Abfragen erheblich reduzieren.
2. Suchoptimierung: Der schnelle Eliminator
In einem verteilten Suchsystem können Bloomfilter als Vorfilter fungieren, um unnötige Suchvorgänge über Shards zu eliminieren.
def search_shards(query):
results = []
for shard in shards:
if shard.bloom_filter.check(query):
results.extend(shard.search(query))
return results
Indem du schnell Shards eliminierst, die die Abfrage definitiv nicht enthalten, kannst du den Netzwerkverkehr reduzieren und die Suchzeiten verbessern.
3. Duplikaterkennung: Der effiziente Deduplicator
Beim Crawlen des Webs oder Verarbeiten großer Datenströme ist die schnelle Erkennung von Duplikaten entscheidend.
def process_item(item):
if not bloom_filter.check(item):
bloom_filter.add(item)
process_new_item(item)
else:
# Möglicherweise schon gesehen, zusätzliche Überprüfung erforderlich
pass
Dieser Ansatz kann den Speicherbedarf erheblich reduzieren im Vergleich zur Aufbewahrung einer vollständigen Liste verarbeiteter Elemente.
Die Feinheiten: Deinen Bloomfilter abstimmen
Wie jedes gute Werkzeug benötigen Bloomfilter eine ordnungsgemäße Abstimmung. Hier sind einige wichtige Überlegungen:
- Größe ist wichtig: Je größer der Filter, desto niedriger die Fehlerrate, aber desto mehr Speicher wird benötigt.
- Hash-Funktionen: Mehr Hash-Funktionen reduzieren Fehlalarme, erhöhen aber die Rechenzeit.
- Erwartete Elementanzahl: Die Kenntnis der Datengröße hilft bei der Optimierung der Filterparameter.
Hier ist eine schnelle Formel, um die Größe deines Bloomfilters zu bestimmen:
import math
def optimal_bloom_filter_size(item_count, false_positive_rate):
m = -(item_count * math.log(false_positive_rate)) / (math.log(2)**2)
k = (m / item_count) * math.log(2)
return int(m), int(k)
# Beispielverwendung
items = 1000000
fp_rate = 0.01
size, hash_count = optimal_bloom_filter_size(items, fp_rate)
print(f"Optimale Größe: {size} Bits")
print(f"Optimale Hash-Anzahl: {hash_count}")
Fallstricke und Überlegungen
Bevor du Bloomfilter überall einsetzt, beachte diese Punkte:
- Fehlalarme sind möglich: Bloomfilter können sagen, dass ein Element möglicherweise vorhanden ist, wenn es nicht ist. Plane dies in deiner Fehlerbehandlung ein.
- Keine Löschung: Standard-Bloomfilter unterstützen das Entfernen von Elementen nicht. Schau dir Counting Bloom Filters an, wenn du diese Funktionalität benötigst.
- Kein Allheilmittel: Obwohl mächtig, sind Bloomfilter nicht für jedes Szenario geeignet. Bewerte deinen Anwendungsfall sorgfältig.
"Mit großer Macht kommt große Verantwortung. Verwende Bloomfilter weise, und sie werden dein Backend gut behandeln." - Onkel Ben (wenn er ein Softwarearchitekt wäre)
Bloomfilter in deinen Stack integrieren
Bist du bereit, Bloomfilter auszuprobieren? Hier sind einige beliebte Bibliotheken, um loszulegen:
- Guava für Java-Entwickler
- pybloom für Python-Enthusiasten
- bloomd für einen eigenständigen Netzwerkdienst
Das große Ganze: Warum sich die Mühe lohnt
Im großen Schema der Dinge sind Bloomfilter mehr als nur ein cleverer Trick. Sie repräsentieren ein breiteres Prinzip im Systemdesign: Manchmal kann ein wenig Unsicherheit zu enormen Leistungsgewinnen führen. Indem wir eine kleine Wahrscheinlichkeit von Fehlalarmen akzeptieren, können wir Systeme schaffen, die schneller, skalierbarer und effizienter sind.
Denkanstoß
Während du Bloomfilter in deiner Architektur implementierst, bedenke diese Fragen:
- Wie kann die probabilistische Natur von Bloomfiltern andere Teile deines Systemdesigns beeinflussen?
- In welchen anderen Szenarien könnte es vorteilhaft sein, perfekte Genauigkeit gegen Geschwindigkeit einzutauschen?
- Wie passt der Einsatz von Bloomfiltern zu den SLAs und Fehlerbudgets deines Systems?
Zusammenfassung: Der Reiz der Bloomfilter
Bloomfilter sind vielleicht nicht mehr der neueste Trend, aber sie sind ein bewährtes, kampferprobtes Werkzeug, das einen Platz in deinem Backend-Werkzeugkasten verdient. Von Caching bis zur Suchoptimierung können diese probabilistischen Kraftpakete deinen verteilten Systemen den Leistungsschub geben, den sie benötigen.
Also, das nächste Mal, wenn du mit einer Datenflut oder einer Abfragekrise konfrontiert bist, denke daran: Manchmal liegt die Lösung im Bloom.
Nun geh und filtere, du großartige Backend-Meister!