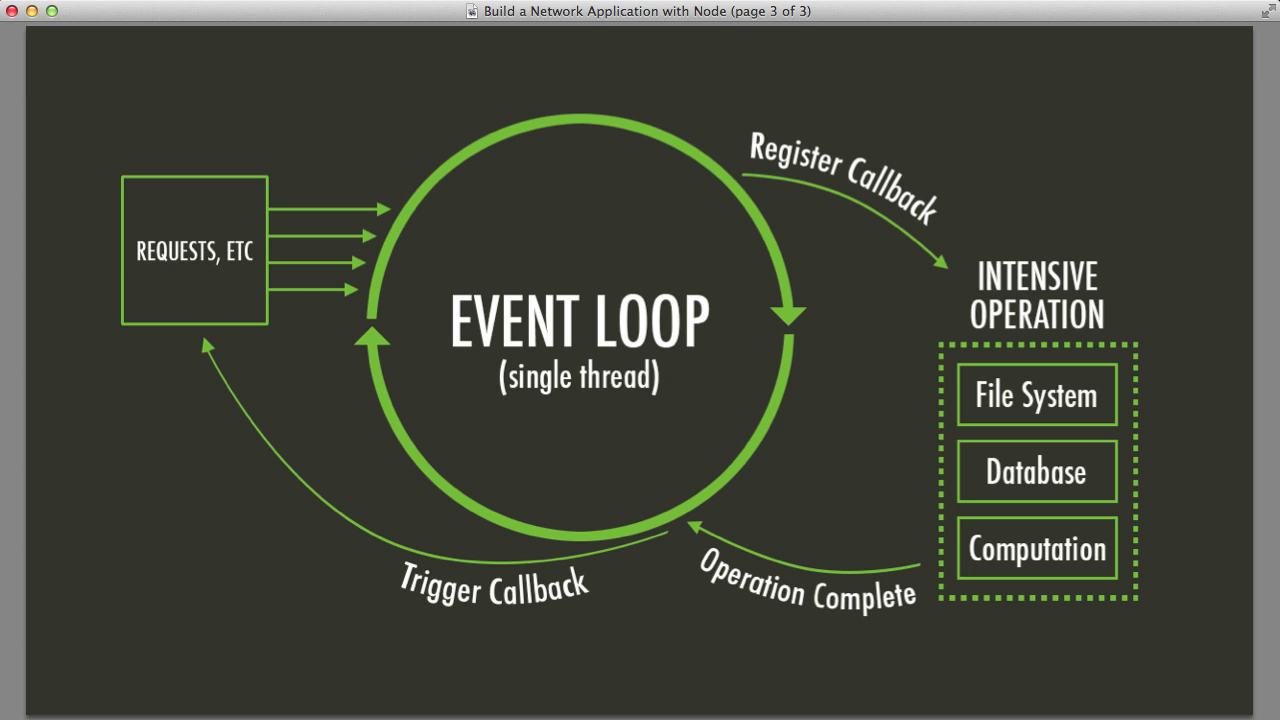
Die Ereignisschleife ist das Herz von Node.js und pumpt asynchrone Operationen durch Ihre Anwendung wie Blut durch Adern. Sie ist einspurig, was bedeutet, dass sie eine Operation nach der anderen abwickeln kann. Lassen Sie sich davon jedoch nicht täuschen – sie ist blitzschnell und effizient.
Hier ist eine vereinfachte Ansicht, wie sie funktioniert:
- Ausführen von synchronem Code
- Verarbeiten von Timern (setTimeout, setInterval)
- Verarbeiten von I/O-Rückrufen
- Verarbeiten von setImmediate()-Rückrufen
- Schließen von Rückrufen
- Wiederholen
Klingt einfach, oder? Nun, die Dinge können kompliziert werden, wenn Sie komplexe Operationen stapeln. Hier kommen unsere fortgeschrittenen Muster ins Spiel.
Muster 1: Worker Threads - Multithreading-Wahnsinn
Erinnern Sie sich, als ich sagte, Node.js sei einspurig? Nun, das ist nicht die ganze Wahrheit. Hier kommen Worker Threads ins Spiel – Node.js' Antwort auf CPU-intensive Aufgaben, die sonst unsere wertvolle Ereignisschleife blockieren würden.
Hier ist ein schnelles Beispiel, wie man Worker Threads verwendet:
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename);
worker.on('message', (message) => {
console.log('Empfangen:', message);
});
worker.postMessage('Hallo, Worker!');
} else {
parentPort.on('message', (message) => {
console.log('Worker empfangen:', message);
parentPort.postMessage('Hallo, Hauptthread!');
});
}
Dieser Code erstellt einen Worker-Thread, der parallel zum Hauptthread laufen kann, sodass Sie schwere Berechnungen auslagern können, ohne die Ereignisschleife zu blockieren. Es ist, als hätten Sie einen persönlichen Assistenten für Ihre CPU-intensiven Aufgaben!
Wann man Worker Threads verwenden sollte
- CPU-gebundene Operationen (komplexe Berechnungen, Datenverarbeitung)
- Parallele Ausführung unabhängiger Aufgaben
- Verbesserung der Leistung synchroner Operationen
Profi-Tipp: Übertreiben Sie es nicht mit Worker Threads! Sie bringen einen Overhead mit sich, also verwenden Sie sie weise für Aufgaben, die wirklich von Parallelisierung profitieren.
Muster 2: Clustering - Weil zwei Köpfe besser sind als einer
Was ist besser als ein Node.js-Prozess? Mehrere Node.js-Prozesse! Das ist die Idee hinter Clustering. Es ermöglicht Ihnen, Kindprozesse zu erstellen, die Serverports teilen, und so die Arbeitslast effektiv auf mehrere CPU-Kerne zu verteilen.
Hier ist ein einfaches Clustering-Beispiel:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} läuft`);
// Arbeiter forken.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`Arbeiter ${worker.process.pid} gestorben`);
});
} else {
// Arbeiter können jede TCP-Verbindung teilen
// In diesem Fall ist es ein HTTP-Server
http.createServer((req, res) => {
res.writeHead(200);
res.end('Hallo Welt\n');
}).listen(8000);
console.log(`Arbeiter ${process.pid} gestartet`);
}
Dieser Code erstellt mehrere Arbeiterprozesse, die jeweils HTTP-Anfragen bearbeiten können. Es ist, als würden Sie Ihren Server klonen und eine Armee von Mini-Servern haben, die bereit sind, eingehende Anfragen zu bearbeiten!
Vorteile des Clustering
- Verbesserte Leistung und Durchsatz
- Bessere Nutzung von Mehrkernsystemen
- Erhöhte Zuverlässigkeit (wenn ein Arbeiter abstürzt, können andere übernehmen)
Denken Sie daran: Mit großer Macht kommt große Verantwortung. Clustering kann die Komplexität Ihrer App erheblich erhöhen, also verwenden Sie es, wenn Sie wirklich horizontal skalieren müssen.
Muster 3: Asynchrone Iteratoren - Das Datenstrom-Biest zähmen
Der Umgang mit großen Datensätzen oder Streams in Node.js kann wie der Versuch sein, aus einem Feuerwehrschlauch zu trinken. Asynchrone Iteratoren kommen zur Rettung, indem sie es Ihnen ermöglichen, Daten Stück für Stück zu verarbeiten, ohne Ihre Ereignisschleife zu überfordern.
Schauen wir uns ein Beispiel an:
const { createReadStream } = require('fs');
const { createInterface } = require('readline');
async function* processFileLines(filename) {
const rl = createInterface({
input: createReadStream(filename),
crlfDelay: Infinity
});
for await (const line of rl) {
yield line;
}
}
(async () => {
for await (const line of processFileLines('riesige_datei.txt')) {
console.log('Verarbeitet:', line);
// Machen Sie etwas mit jeder Zeile
}
})();
Dieser Code liest eine potenziell riesige Datei Zeile für Zeile und ermöglicht es Ihnen, jede Zeile zu verarbeiten, ohne die gesamte Datei in den Speicher zu laden. Es ist, als hätten Sie ein Förderband für Ihre Daten, das sie Ihnen in einem überschaubaren Tempo zuführt!
Warum asynchrone Iteratoren großartig sind
- Effiziente Speichernutzung für große Datensätze
- Natürliche Art, asynchrone Datenströme zu handhaben
- Verbesserte Lesbarkeit für komplexe Datenverarbeitungspipelines
Alles zusammenfügen: Ein Szenario aus der realen Welt
Stellen Sie sich vor, wir bauen ein Log-Analyse-System, das massive Log-Dateien verarbeiten, CPU-intensive Berechnungen durchführen und Ergebnisse über eine API bereitstellen muss. So könnten wir diese Muster kombinieren:
const cluster = require('cluster');
const { Worker } = require('worker_threads');
const express = require('express');
const { processFileLines } = require('./fileProcessor');
if (cluster.isMaster) {
console.log(`Master ${process.pid} läuft`);
// Arbeiter für den API-Server forken
for (let i = 0; i < 2; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`Arbeiter ${worker.process.pid} gestorben`);
});
} else {
const app = express();
app.get('/analyze', async (req, res) => {
const results = [];
const worker = new Worker('./analyzeWorker.js');
for await (const line of processFileLines('riesige_log_datei.txt')) {
worker.postMessage(line);
}
worker.on('message', (result) => {
results.push(result);
});
worker.on('exit', () => {
res.json(results);
});
});
app.listen(3000, () => console.log(`Arbeiter ${process.pid} gestartet`));
}
In diesem Beispiel verwenden wir:
- Clustering, um mehrere API-Server-Prozesse zu erstellen
- Worker Threads, um CPU-intensive Log-Analysen auszulagern
- Asynchrone Iteratoren, um große Log-Dateien effizient zu verarbeiten
Diese Kombination ermöglicht es uns, mehrere gleichzeitige Anfragen zu bearbeiten, große Dateien effizient zu verarbeiten und komplexe Berechnungen durchzuführen, ohne die Ereignisschleife zu blockieren. Es ist wie eine gut geölte Maschine, bei der jeder Teil seine Aufgabe kennt und harmonisch mit den anderen zusammenarbeitet!
Zusammenfassung: Gelernte Lektionen
Wie wir gesehen haben, geht es beim Management von Nebenläufigkeit in Node.js darum, die Ereignisschleife zu verstehen und zu wissen, wann man zu fortgeschrittenen Mustern greifen sollte. Hier sind die wichtigsten Erkenntnisse:
- Verwenden Sie Worker Threads für CPU-intensive Aufgaben, die die Ereignisschleife blockieren würden
- Implementieren Sie Clustering, um die Vorteile von Mehrkernsystemen zu nutzen und die Skalierbarkeit zu verbessern
- Nutzen Sie asynchrone Iteratoren für die effiziente Verarbeitung großer Datensätze oder Streams
- Kombinieren Sie diese Muster strategisch basierend auf Ihrem spezifischen Anwendungsfall
Denken Sie daran, mit großer Macht kommt große... Komplexität. Diese Muster sind mächtige Werkzeuge, aber sie bringen auch neue Herausforderungen in Bezug auf Debugging, Zustandsverwaltung und die gesamte Anwendungsarchitektur mit sich. Verwenden Sie sie mit Bedacht und profilieren Sie Ihre Anwendung immer, um sicherzustellen, dass Sie tatsächlich von diesen fortgeschrittenen Techniken profitieren.
Denkanstöße
Während Sie tiefer in die Welt der Node.js-Nebenläufigkeit eintauchen, hier einige Fragen zum Nachdenken:
- Wie könnten diese Muster das Fehlerhandling und die Widerstandsfähigkeit Ihrer Anwendung beeinflussen?
- Was sind die Kompromisse zwischen der Verwendung von Worker Threads und dem Starten separater Prozesse?
- Wie können Sie Anwendungen, die diese fortgeschrittenen Nebenläufigkeitsmuster verwenden, effektiv überwachen und debuggen?
Die Reise zur Beherrschung der Node.js-Nebenläufigkeit ist fortlaufend, aber mit diesen Mustern sind Sie auf dem besten Weg, blitzschnelle, effiziente und skalierbare Anwendungen zu erstellen. Gehen Sie nun voran und erobern Sie diese Ereignisschleife!
Denken Sie daran: Der beste Code ist nicht immer der komplexeste. Manchmal kann eine gut strukturierte einspurige Anwendung eine schlecht implementierte mehrspurige übertreffen. Messen, profilieren und optimieren Sie immer basierend auf realen Leistungsdaten.
Viel Spaß beim Programmieren, und mögen Ihre Ereignisschleifen immer ungebrochen sein (es sei denn, Sie wollen es so)!