Graceful Degradation bedeutet, dass Ihr System funktionsfähig bleibt, auch wenn es nicht bei 100% ist. Wir werden Strategien wie Circuit Breakers, Rate Limiting und Priorisierung erkunden, um Ihrem Backend zu helfen, jedem Sturm zu trotzen. Schnallen Sie sich an; es wird eine holprige (aber lehrreiche) Fahrt!
Warum sich mit Graceful Degradation beschäftigen?
Seien wir ehrlich: In einer idealen Welt würden unsere Systeme rund um die Uhr fehlerfrei laufen. Aber wir leben in der realen Welt, wo Murphys Gesetz immer um die Ecke lauert. Graceful Degradation ist unsere Art, Murphy die Stirn zu bieten und zu sagen: "Netter Versuch, aber wir haben das im Griff."
Hier ist, warum es wichtig ist:
- Hält kritische Funktionen am Leben, wenn es Probleme gibt
- Verhindert Kaskadenfehler, die Ihr gesamtes System lahmlegen können
- Verbessert die Benutzererfahrung in stressigen Zeiten
- Gibt Ihnen Zeit, Probleme zu beheben, ohne dass eine vollständige Krise entsteht
Strategien für Graceful Degradation
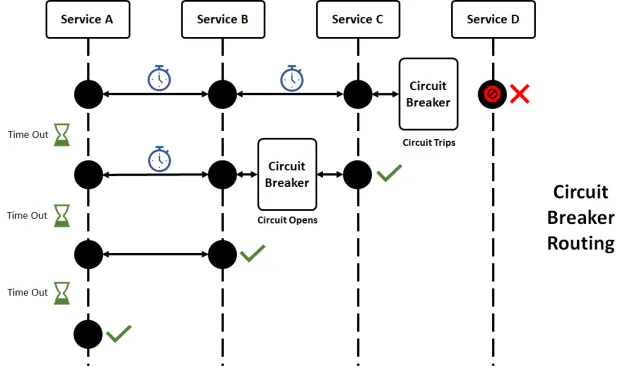
1. Circuit Breakers: Die Sicherung Ihres Systems
Erinnern Sie sich daran, wie Sie als Kind eine Sicherung durchgebrannt haben, als Sie zu viele Weihnachtslichter angeschlossen haben? Circuit Breakers in der Software funktionieren ähnlich und schützen Ihr System vor Überlastung.
Hier ist eine einfache Implementierung mit der Hystrix-Bibliothek:
public class ExampleCommand extends HystrixCommand {
private final String name;
public ExampleCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
// Dies könnte ein API-Aufruf oder eine Datenbankabfrage sein
return "Hallo " + name + "!";
}
@Override
protected String getFallback() {
return "Hallo Gast!";
}
}
In diesem Beispiel, wenn die run()-Methode fehlschlägt oder zu lange dauert, greift der Circuit Breaker ein und ruft getFallback() auf. Es ist wie ein Notstromaggregat für Ihren Code!
2. Rate Limiting: Ihrer API Manieren beibringen
Rate Limiting ist wie ein Türsteher in einem Club. Sie wollen nicht, dass zu viele Anfragen auf einmal hereinkommen, sonst könnte es chaotisch werden. Hier ist, wie Sie es mit Spring Boot und Bucket4j implementieren könnten:
@RestController
public class ApiController {
private final Bucket bucket;
public ApiController() {
Bandwidth limit = Bandwidth.classic(20, Refill.greedy(20, Duration.ofMinutes(1)));
this.bucket = Bucket.builder()
.addLimit(limit)
.build();
}
@GetMapping("/api/resource")
public ResponseEntity getResource() {
if (bucket.tryConsume(1)) {
return ResponseEntity.ok("Hier ist Ihre Ressource!");
}
return ResponseEntity.status(429).body("Zu viele Anfragen, bitte versuchen Sie es später erneut.");
}
}
Diese Konfiguration erlaubt 20 Anfragen pro Minute. Mehr als das, und Sie werden höflich gebeten, später wiederzukommen. Es ist, als hätte Ihre API gelernt, in der Schlange zu stehen!
3. Priorisierung: Nicht alle Anfragen sind gleich
Wenn es hart auf hart kommt, müssen Sie wissen, was Priorität hat. Es ist wie die Triage in einer Notaufnahme – kritische Operationen zuerst, Katzen-GIFs später (sorry, Katzenliebhaber).
Erwägen Sie die Implementierung einer Prioritätswarteschlange für Ihre Anfragen:
public class PriorityRequestQueue {
private PriorityQueue queue;
public PriorityRequestQueue() {
this.queue = new PriorityQueue<>((r1, r2) -> r2.getPriority() - r1.getPriority());
}
public void addRequest(Request request) {
queue.offer(request);
}
public Request processNextRequest() {
return queue.poll();
}
}
Dies stellt sicher, dass Anfragen mit hoher Priorität (wie Zahlungen oder kritische Benutzeraktionen) zuerst bearbeitet werden, wenn Ressourcen begrenzt sind.
Die Kunst des eleganten Scheiterns
Jetzt, da wir einige Strategien behandelt haben, sprechen wir über die Kunst des eleganten Scheiterns. Es geht nicht nur darum, einen vollständigen Zusammenbruch zu vermeiden; es geht darum, Würde im Angesicht von Widrigkeiten zu bewahren. Hier sind einige Tipps:
- Klare Kommunikation: Seien Sie transparent mit Ihren Benutzern, wenn Sie Dienste herabstufen. Ein einfaches "Wir erleben eine hohe Nachfrage, einige Funktionen sind möglicherweise vorübergehend nicht verfügbar" wirkt Wunder.
- Stufenweise Herabstufung: Gehen Sie nicht von 100 auf 0. Deaktivieren Sie zuerst nicht-kritische Funktionen und halten Sie die Kernfunktionalität so lange wie möglich intakt.
- Intelligente Wiederholungen: Implementieren Sie exponentielles Backoff für Wiederholungen, um bereits gestresste Dienste nicht zu überlasten.
- Caching-Strategien: Nutzen Sie Caching klug, um die Belastung der Backend-Dienste während Spitzenzeiten zu reduzieren.
Überwachung: Ihr Frühwarnsystem
Die Implementierung von Graceful Degradation-Strategien ist großartig, aber wie wissen Sie, wann Sie sie auslösen müssen? Hier kommt die Überwachung ins Spiel – das Frühwarnsystem Ihres Systems.
Erwägen Sie die Verwendung von Tools wie Prometheus und Grafana, um wichtige Metriken im Auge zu behalten:
- Antwortzeiten
- Fehlerraten
- CPU- und Speichernutzung
- Warteschlangenlängen
Richten Sie Alarme ein, die nicht nur ausgelöst werden, wenn es schlecht läuft, sondern auch, wenn es ein wenig unsicher aussieht. Es ist wie eine Wettervorhersage für Ihr System – Sie möchten über den Sturm Bescheid wissen, bevor er eintrifft.
Testen Ihrer Degradationsstrategien
Sie würden keinen Code ohne Testen bereitstellen, oder? (Oder?!) Dasselbe gilt für Ihre Degradationsstrategien. Chaos Engineering ist die Kunst, Dinge absichtlich kaputt zu machen.
Tools wie Chaos Monkey können Ihnen helfen, Ausfälle und Hochlastszenarien in einer kontrollierten Umgebung zu simulieren. Es ist wie eine Feuerübung für Ihr System. Sicher, es kann ein wenig nervenaufreibend sein, aber es ist besser, herauszufinden, dass Ihre Sprinkleranlage während einer Übung nicht funktioniert, als während eines echten Feuers.
Beispiel aus der Praxis: Der Ansatz von Netflix
Werfen wir einen kurzen Blick darauf, wie der Streaming-Riese Netflix mit Graceful Degradation umgeht. Sie verwenden eine Technik namens "Fallback nach Priorität". Hier ist eine vereinfachte Version ihres Ansatzes:
- Versuchen Sie, personalisierte Empfehlungen für einen Benutzer abzurufen.
- Wenn das fehlschlägt, greifen Sie auf beliebte Titel in ihrer Region zurück.
- Wenn regionale Daten nicht verfügbar sind, zeigen Sie insgesamt beliebte Titel an.
- Als letzten Ausweg zeigen Sie eine statische, vordefinierte Liste von Titeln an.
Dies stellt sicher, dass Benutzer immer etwas sehen, auch wenn es nicht die ideale, personalisierte Erfahrung ist. Es ist ein großartiges Beispiel dafür, wie man Funktionalität herabstufen kann, während man dennoch Wert bietet.
Fazit: Umarmen Sie das Chaos
Das Design für Graceful Degradation geht nicht nur darum, Ausfälle zu bewältigen; es geht darum, die chaotische Natur verteilter Systeme zu akzeptieren. Es bedeutet, dass Dinge schiefgehen werden und man dafür plant. Es ist der Unterschied zwischen "Ups, unser Fehler!" und "Wir haben das unter Kontrolle."
Denken Sie daran:
- Implementieren Sie Circuit Breakers, um Kaskadenfehler zu verhindern
- Verwenden Sie Rate Limiting, um Hochlastszenarien zu bewältigen
- Priorisieren Sie kritische Operationen, wenn Ressourcen knapp sind
- Kommunizieren Sie klar mit Benutzern während herabgestufter Zustände
- Überwachen, testen und verbessern Sie kontinuierlich Ihre Degradationsstrategien
Indem Sie diese Strategien befolgen, bauen Sie nicht nur ein System; Sie bauen einen widerstandsfähigen, kampferprobten Krieger, der bereit ist, jedem Chaos, das die digitale Welt ihm entgegenwirft, zu trotzen. Gehen Sie nun hinaus und degradieren Sie mit Anmut!
"Der wahre Test eines Systems ist nicht, wie es funktioniert, wenn alles gut läuft, sondern wie es sich verhält, wenn alles schiefgeht." - Anonymer DevOps-Philosoph
Haben Sie Geschichten über Graceful Degradation in Ihren Systemen? Teilen Sie sie in den Kommentaren! Schließlich ist der Albtraum eines Entwicklers die Lerngelegenheit eines anderen. Viel Spaß beim Programmieren, und mögen Ihre Systeme immer mit Anmut und Stil degradieren!