Das Anheften von Goroutinen an Betriebssystem-Threads kann die NUMA-Strafen und die Sperrkonkurrenz in Go-basierten HFT-Systemen erheblich reduzieren. Wir werden untersuchen, wie man runtime.LockOSThread() nutzt, die Thread-Affinität verwaltet und Ihren Go-Code für Multi-Socket-Architekturen optimiert.
Der NUMA-Albtraum
Bevor wir uns in die Details des Goroutine-Anheftens stürzen, lassen Sie uns kurz rekapitulieren, warum NUMA-Architekturen (Non-Uniform Memory Access) für HFT-Systeme problematisch sein können:
- Die Speicherzugriffsverzögerung variiert je nachdem, welcher CPU-Kern auf welchen Speicherbank zugreift
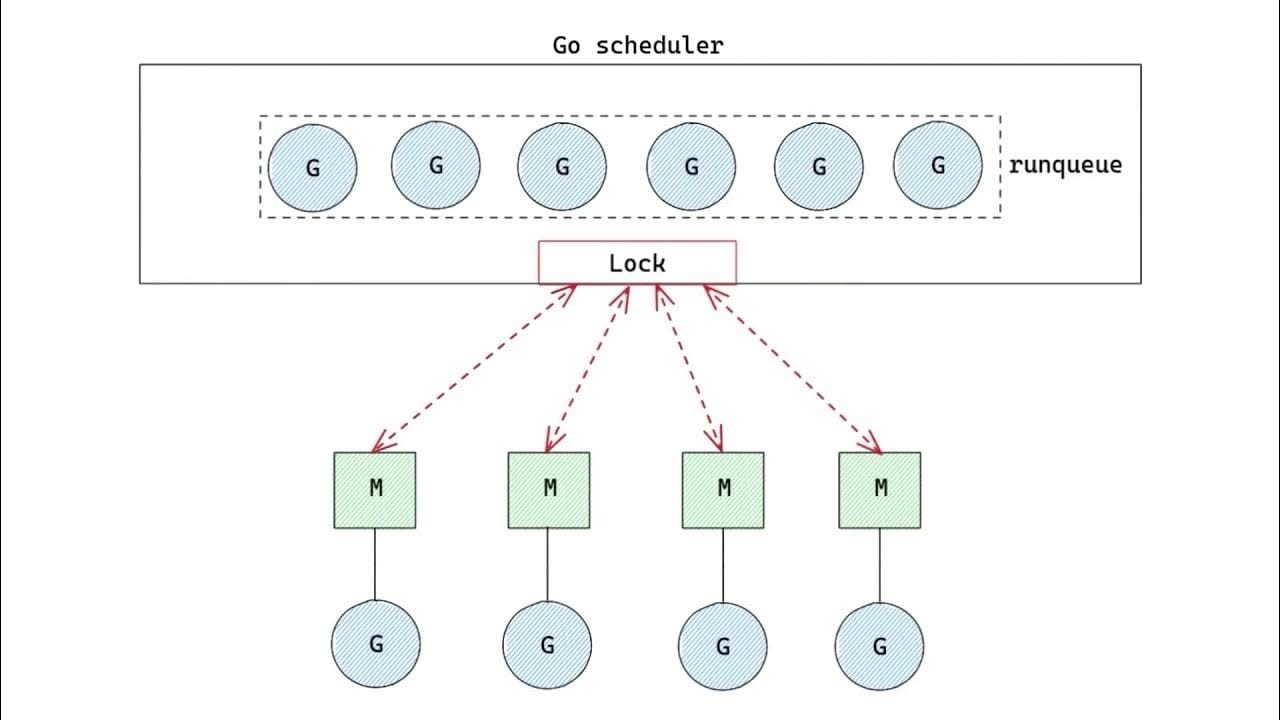
- Der Go-Scheduler berücksichtigt standardmäßig nicht die NUMA-Topologie beim Planen von Goroutinen
- Dies kann zu häufigen Speicherzugriffen über Sockel hinweg führen, was die Leistung beeinträchtigt
In der Welt des HFT, wo jede Nanosekunde zählt, können diese NUMA-Strafen den Unterschied zwischen Gewinn und Verlust ausmachen. Aber keine Sorge, wir haben die Werkzeuge, um dieses Problem zu zähmen!
Goroutinen anheften: Das Geheimrezept
Der Schlüssel zur Minderung von NUMA-Problemen in Go besteht darin, Goroutinen an bestimmte Betriebssystem-Threads zu heften, die dann an bestimmte CPU-Kerne gebunden werden können. Dies stellt sicher, dass unsere Goroutinen an Ort und Stelle bleiben und nicht über NUMA-Knoten wandern. So können wir das erreichen:
1. Die aktuelle Goroutine an ihren OS-Thread binden
func init() {
runtime.LockOSThread()
}
Dieser Funktionsaufruf stellt sicher, dass die aktuelle Goroutine an den OS-Thread gebunden ist, auf dem sie läuft. Es ist wichtig, dies zu Beginn Ihres Programms oder in jeder Goroutine, die angeheftet werden muss, aufzurufen.
2. Thread-Affinität festlegen
Nachdem wir unsere Goroutine an einen OS-Thread gebunden haben, müssen wir dem Betriebssystem mitteilen, auf welchem CPU-Kern dieser Thread laufen soll. Leider bietet Go keine native Möglichkeit, dies zu tun, daher müssen wir etwas cgo-Magie verwenden:
// #include <pthread.h>
// #include <stdlib.h>
import "C"
import "unsafe"
func setThreadAffinity(cpuID int) {
runtime.LockOSThread()
var cpuset C.cpu_set_t
C.CPU_ZERO(&cpuset)
C.CPU_SET(C.int(cpuID), &cpuset)
thread := C.pthread_self()
_, err := C.pthread_setaffinity_np(thread, C.size_t(unsafe.Sizeof(cpuset)), &cpuset)
if err != nil {
panic(err)
}
}
Diese Funktion verwendet die POSIX-Threads-API, um die Affinität des aktuellen Threads zu einem bestimmten CPU-Kern festzulegen. Sie müssen diese Funktion von jeder Goroutine aus aufrufen, die an einen bestimmten Kern angeheftet werden muss.
Alles zusammenfügen: Eine Hochleistungs-Marktdaten-Pipeline
Jetzt, da wir die Bausteine haben, sehen wir uns an, wie wir dies in einem realen HFT-Szenario anwenden können. Wir erstellen eine einfache Marktdaten-Pipeline, die eingehende Ticks verarbeitet und einige grundlegende Statistiken berechnet.
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
type MarketData struct {
Symbol string
Price float64
}
func marketDataProcessor(id int, inputChan <-chan MarketData, wg *sync.WaitGroup) {
defer wg.Done()
// Diese Goroutine an einen bestimmten CPU-Kern anheften
setThreadAffinity(id % runtime.NumCPU())
var count int
var sum float64
start := time.Now()
for data := range inputChan {
count++
sum += data.Price
if count % 1000000 == 0 {
avgPrice := sum / float64(count)
elapsed := time.Since(start)
fmt.Printf("Prozessor %d: %d Ticks verarbeitet, Durchschnittspreis: %.2f, Zeit: %v\n", id, count, avgPrice, elapsed)
start = time.Now()
count = 0
sum = 0
}
}
}
func main() {
runtime.GOMAXPROCS(runtime.NumCPU())
numProcessors := 4
inputChan := make(chan MarketData, 10000)
var wg sync.WaitGroup
// Marktdatenprozessoren starten
for i := 0; i < numProcessors; i++ {
wg.Add(1)
go marketDataProcessor(i, inputChan, &wg)
}
// Eingehende Marktdaten simulieren
go func() {
for i := 0; ; i++ {
inputChan <- MarketData{
Symbol: fmt.Sprintf("STOCK%d", i%100),
Price: float64(i % 10000) / 100,
}
}
}()
wg.Wait()
}
In diesem Beispiel erstellen wir mehrere Marktdatenprozessoren, die jeweils an einen bestimmten CPU-Kern angeheftet sind. Dieser Ansatz hilft uns, die Nutzung unseres Mehrkernsystems zu maximieren und gleichzeitig NUMA-Strafen zu minimieren.
Die Vor- und Nachteile des Goroutine-Anheftens
Bevor Sie sich vollständig dem Goroutine-Anheften widmen, ist es wichtig, die Kompromisse zu verstehen:
Vorteile:
- Reduzierte NUMA-Strafen in Multi-Socket-Systemen
- Verbesserte Cache-Lokalität und reduzierte Cache-Verdrängung
- Bessere Kontrolle über die Arbeitslastverteilung über CPU-Kerne
- Potenzial für signifikante Leistungsverbesserungen in HFT-Szenarien
Nachteile:
- Erhöhte Komplexität im Code und Systemdesign
- Potenzial für ungleichmäßige Lastverteilung, wenn nicht sorgfältig verwaltet
- Verlust einiger der eingebauten Planungsfunktionen von Go
- Kann betriebssystemspezifischen Code für die Verwaltung der Thread-Affinität erfordern
Die Auswirkungen messen: Vorher und Nachher
Um die Vorteile des Goroutine-Anheftens wirklich zu schätzen, ist es entscheidend, die Leistung Ihres Systems vor und nach der Implementierung zu messen. Hier sind einige wichtige Metriken, auf die Sie sich konzentrieren sollten:
- Latenz-Perzentile (p50, p99, p99.9)
- Durchsatz (verarbeitete Nachrichten pro Sekunde)
- CPU-Auslastung über Kerne hinweg
- Speicherzugriffsmuster (mit Tools wie Intel VTune oder AMD uProf)
Profi-Tipp: Verwenden Sie ein Tool wie pprof, um CPU- und Speicherprofile Ihrer Anwendung vor und nach der Implementierung des Goroutine-Anheftens zu erstellen. Dies kann wertvolle Einblicke in die Auswirkungen Ihrer Optimierungen auf das Systemverhalten bieten.
Über das Anheften hinaus: Zusätzliche Optimierungen für HFT-Workloads
Während das Anheften von Goroutinen eine leistungsstarke Technik ist, ist es nur ein Teil des Puzzles, wenn es darum geht, Go für HFT-Workloads zu optimieren. Hier sind einige zusätzliche Strategien, die Sie in Betracht ziehen sollten:
1. Speicherzuweisungsoptimierung
Minimieren Sie Garbage-Collection-Pausen, indem Sie Zuweisungen reduzieren:
- Verwenden Sie sync.Pool für häufig zugewiesene Objekte
- Erwägen Sie die Verwendung von Arrays anstelle von Slices für Daten mit fester Größe
- Preallokieren Sie Puffer, wenn möglich
2. Sperrfreie Datenstrukturen
Reduzieren Sie die Konkurrenz, indem Sie atomare Operationen und sperrfreie Datenstrukturen verwenden:
import "sync/atomic"
type AtomicFloat64 struct{ v uint64 }
func (f *AtomicFloat64) Store(val float64) {
atomic.StoreUint64(&f.v, math.Float64bits(val))
}
func (f *AtomicFloat64) Load() float64 {
return math.Float64frombits(atomic.LoadUint64(&f.v))
}
3. SIMD-Anweisungen
Nutzen Sie SIMD (Single Instruction, Multiple Data)-Anweisungen für die parallele Verarbeitung von Marktdaten. Während Go keine direkte SIMD-Unterstützung bietet, können Sie Assembly oder cgo verwenden, um auf diese leistungsstarken Anweisungen zuzugreifen.
Zusammenfassung: Die Zukunft von Go im HFT
Wie wir gesehen haben, kann Go mit ein wenig Aufwand und einigen fortgeschrittenen Techniken wie dem Anheften von Goroutinen ein beeindruckendes Werkzeug im HFT-Bereich sein. Aber die Reise endet hier nicht. Das Go-Team arbeitet ständig an Verbesserungen der Laufzeit und des Schedulers, die einige dieser manuellen Optimierungen in Zukunft überflüssig machen könnten.
Denken Sie daran, dass vorzeitige Optimierung die Wurzel allen Übels ist. Profilieren Sie Ihre Anwendung immer zuerst, um echte Engpässe zu identifizieren, bevor Sie sich in fortgeschrittene Techniken wie das Anheften von Goroutinen stürzen. Und wenn Sie optimieren, messen, messen, messen!
Viel Erfolg beim Handel, und mögen Ihre Goroutinen immer den Weg nach Hause zu den richtigen CPU-Kernen finden!
"In der Welt des HFT zählt jede Nanosekunde. Aber in der Welt der Softwareentwicklung zählen Lesbarkeit und Wartbarkeit noch mehr. Finden Sie das richtige Gleichgewicht, und Sie werden erfolgreich sein." - Weiser alter Gopher
Weiterführende Literatur
- Go Runtime Package Dokumentation
- Scheduling in Go von William Kennedy
- Go GitHub Issue: Unterstützung für CPU-Affinität
- Go Runtime Scheduler von Kavya Joshi
Gehen Sie nun hinaus und erobern Sie diese NUMA-Knoten! Und denken Sie daran, mit großer Macht kommt große Verantwortung. Nutzen Sie Ihre neu erworbenen Fähigkeiten im Goroutine-Anheften weise!