Effektives Fehlerhandling in ereignisgesteuerten Systemen, insbesondere bei der Verwendung von Kafka, erfordert die Weitergabe von kontextbewussten Fehlern über verschiedene Topics. Wir werden Strategien untersuchen, um den Fehlerkontext beizubehalten, Fehlerereignisse zu entwerfen und robuste Fehlerbehandlungsmuster zu implementieren. Am Ende werden Sie in der Lage sein, das Chaos verteilter Fehler zu bändigen und Ihr System reibungslos am Laufen zu halten.
Das Dilemma der Fehlerbehandlung
Ereignisgesteuerte Architekturen eignen sich hervorragend zum Aufbau skalierbarer und lose gekoppelter Systeme. Aber wenn es um die Fehlerbehandlung geht, kann es... interessant werden. Anders als in monolithischen Anwendungen, in denen man den Ursprung eines Fehlers leicht nachverfolgen kann, stellen verteilte Systeme eine einzigartige Herausforderung dar: Fehler können überall und jederzeit auftreten und ihre Auswirkungen können sich durch das gesamte System ziehen.
Was macht also die Fehlerbehandlung in ereignisgesteuerten Systemen, insbesondere bei der Verwendung von Kafka, so knifflig?
- Asynchrone Natur der Ereignisse
- Entkoppelte Dienste
- Potenzial für kaskadierende Fehler
- Verlust des Fehlerkontexts über Dienstgrenzen hinweg
Gehen wir diese Herausforderungen direkt an und erkunden, wie wir kontextbewusste Fehler über Kafka-Topics wie Profis weitergeben können.
Entwurf kontextbewusster Fehlerereignisse
Der erste Schritt zu einer effektiven Fehlerbehandlung besteht darin, Fehlerereignisse zu entwerfen, die genügend Kontext enthalten, um nützlich zu sein. So könnte ein gut gestaltetes Fehlerereignis aussehen:
{
"errorId": "e12345-67890-abcdef",
"timestamp": "2023-04-15T14:30:00Z",
"sourceService": "payment-processor",
"errorType": "PAYMENT_FAILURE",
"errorMessage": "Kreditkarte abgelehnt",
"correlationId": "order-123456",
"stackTrace": "...",
"metadata": {
"orderId": "order-123456",
"userId": "user-789012",
"amount": 99.99
}
}
Dieses Fehlerereignis enthält:
- Eine eindeutige Fehler-ID zur Nachverfolgung
- Zeitstempel, wann der Fehler aufgetreten ist
- Quellservice zur Identifizierung des Ursprungs des Fehlers
- Fehlertyp und Nachricht für schnelles Verständnis
- Korrelation-ID zur Verknüpfung verwandter Ereignisse
- Stack-Trace für detailliertes Debugging
- Relevante Metadaten zur Bereitstellung von Kontext
Implementierung der Fehlerweitergabe
Jetzt, da wir unsere Fehlerereignisstruktur haben, schauen wir uns an, wie wir die Fehlerweitergabe über Kafka-Topics implementieren können.
1. Erstellen Sie ein dediziertes Fehler-Topic
Erstellen Sie zunächst ein dediziertes Kafka-Topic für Fehler. Dies ermöglicht es Ihnen, die Fehlerbehandlung zu zentralisieren und Fehler separat von regulären Ereignissen zu überwachen und zu verarbeiten.
kafka-topics.sh --create --topic error-events --partitions 3 --replication-factor 3 --bootstrap-server localhost:9092
2. Implementieren Sie Fehlerproduzenten
Implementieren Sie in Ihren Diensten Fehlerproduzenten, die Fehlerereignisse an das dedizierte Fehler-Topic senden, wenn Ausnahmen auftreten. Hier ist ein einfaches Beispiel mit Java und dem Kafka-Client:
public class ErrorProducer {
private final KafkaProducer producer;
private static final String ERROR_TOPIC = "error-events";
public ErrorProducer(Properties kafkaProps) {
this.producer = new KafkaProducer<>(kafkaProps);
}
public void sendErrorEvent(ErrorEvent errorEvent) {
String errorJson = convertToJson(errorEvent);
ProducerRecord record = new ProducerRecord<>(ERROR_TOPIC, errorEvent.getErrorId(), errorJson);
producer.send(record, (metadata, exception) -> {
if (exception != null) {
// Behandeln Sie den Fall, dass das Senden des Fehlerereignisses selbst fehlschlägt
System.err.println("Fehler beim Senden des Fehlerereignisses: " + exception.getMessage());
}
});
}
private String convertToJson(ErrorEvent errorEvent) {
// Implementieren Sie hier die JSON-Konvertierungslogik
}
}
3. Implementieren Sie Fehlerkonsumenten
Erstellen Sie Fehlerkonsumenten, die die Fehlerereignisse aus dem Fehler-Topic verarbeiten. Diese Konsumenten können verschiedene Aktionen ausführen, wie z.B. Protokollierung, Alarmierung oder Auslösen von Kompensationsaktionen.
public class ErrorConsumer {
private final KafkaConsumer consumer;
private static final String ERROR_TOPIC = "error-events";
public ErrorConsumer(Properties kafkaProps) {
this.consumer = new KafkaConsumer<>(kafkaProps);
consumer.subscribe(Collections.singletonList(ERROR_TOPIC));
}
public void consumeErrors() {
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
ErrorEvent errorEvent = parseErrorEvent(record.value());
processError(errorEvent);
}
}
}
private ErrorEvent parseErrorEvent(String json) {
// Implementieren Sie hier die JSON-Parsing-Logik
}
private void processError(ErrorEvent errorEvent) {
// Implementieren Sie die Fehlerverarbeitungslogik (Protokollierung, Alarmierung usw.)
}
}
Erweiterte Fehlerbehandlungsmuster
Jetzt, da wir die Grundlagen beherrschen, lassen Sie uns einige erweiterte Muster für die Fehlerbehandlung in ereignisgesteuerten Systemen erkunden.
1. Circuit Breaker Muster
Implementieren Sie Circuit Breaker, um kaskadierende Fehler zu verhindern, wenn ein Dienst wiederholt Fehler aufweist. Dieses Muster kann Ihrem System helfen, sich anmutig zu verschlechtern und zu erholen.
public class CircuitBreaker {
private final long timeout;
private final int failureThreshold;
private int failureCount;
private long lastFailureTime;
private State state;
public CircuitBreaker(long timeout, int failureThreshold) {
this.timeout = timeout;
this.failureThreshold = failureThreshold;
this.state = State.CLOSED;
}
public boolean allowRequest() {
if (state == State.OPEN) {
if (System.currentTimeMillis() - lastFailureTime > timeout) {
state = State.HALF_OPEN;
return true;
}
return false;
}
return true;
}
public void recordSuccess() {
failureCount = 0;
state = State.CLOSED;
}
public void recordFailure() {
failureCount++;
lastFailureTime = System.currentTimeMillis();
if (failureCount >= failureThreshold) {
state = State.OPEN;
}
}
private enum State {
CLOSED, OPEN, HALF_OPEN
}
}
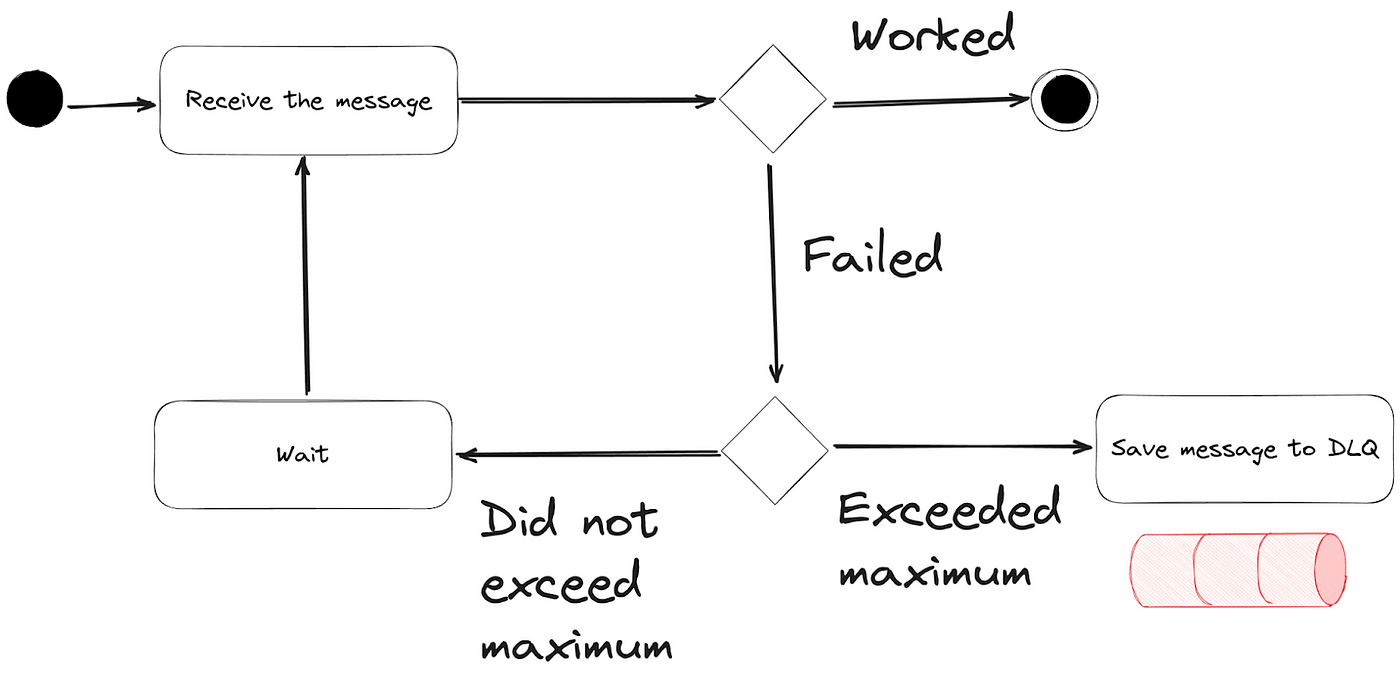
2. Dead Letter Queue
Implementieren Sie eine Dead Letter Queue (DLQ) für Nachrichten, die wiederholt fehlschlagen. Dies ermöglicht es Ihnen, problematische Ereignisse für eine spätere Analyse und erneute Verarbeitung zu isolieren.
public class DeadLetterQueue {
private final KafkaProducer producer;
private static final String DLQ_TOPIC = "dead-letter-queue";
public DeadLetterQueue(Properties kafkaProps) {
this.producer = new KafkaProducer<>(kafkaProps);
}
public void sendToDLQ(String key, String value, String reason) {
DLQEvent dlqEvent = new DLQEvent(key, value, reason);
String dlqJson = convertToJson(dlqEvent);
ProducerRecord record = new ProducerRecord<>(DLQ_TOPIC, key, dlqJson);
producer.send(record);
}
private String convertToJson(DLQEvent dlqEvent) {
// Implementieren Sie hier die JSON-Konvertierungslogik
}
}
3. Wiederholen mit Backoff
Implementieren Sie einen Wiederholungsmechanismus mit exponentiellem Backoff für vorübergehende Fehler. Dies kann Ihrem System helfen, sich von temporären Ausfällen zu erholen, ohne die fehlerhafte Komponente zu überlasten.
public class RetryWithBackoff {
private final int maxRetries;
private final long initialBackoff;
public RetryWithBackoff(int maxRetries, long initialBackoff) {
this.maxRetries = maxRetries;
this.initialBackoff = initialBackoff;
}
public void executeWithRetry(Runnable task) throws Exception {
int attempts = 0;
while (attempts < maxRetries) {
try {
task.run();
return;
} catch (Exception e) {
attempts++;
if (attempts >= maxRetries) {
throw e;
}
long backoff = initialBackoff * (long) Math.pow(2, attempts - 1);
Thread.sleep(backoff);
}
}
}
}
Überwachung und Beobachtbarkeit
Die Implementierung einer robusten Fehlerbehandlung ist großartig, aber Sie müssen auch die Gesundheit Ihres Systems im Auge behalten. Hier sind einige Tipps zur Überwachung und Beobachtbarkeit:
- Verwenden Sie verteilte Tracing-Tools wie Jaeger oder Zipkin, um Anfragen über Dienste hinweg zu verfolgen
- Implementieren Sie Health-Check-Endpunkte in Ihren Diensten
- Richten Sie Alarme basierend auf Fehlerraten und -mustern ein
- Verwenden Sie Log-Aggregation-Tools, um Protokolle zu zentralisieren und zu analysieren
- Erstellen Sie Dashboards, um Fehlertrends und Systemgesundheit zu visualisieren
Fazit: Das Chaos bändigen
Fehlerbehandlung in ereignisgesteuerten Systemen, insbesondere bei der Arbeit mit Kafka, kann herausfordernd sein. Aber mit dem richtigen Ansatz können Sie potenzielles Chaos in eine gut geölte Maschine verwandeln. Durch das Entwerfen kontextbewusster Fehlerereignisse, die Implementierung einer ordnungsgemäßen Fehlerweitergabe und die Nutzung fortschrittlicher Fehlerbehandlungsmuster sind Sie auf dem besten Weg, widerstandsfähige und wartbare ereignisgesteuerte Systeme zu erstellen.
Denken Sie daran, dass effektive Fehlerbehandlung nicht nur darin besteht, Ausnahmen abzufangen – es geht darum, sinnvollen Kontext bereitzustellen, schnelles Debugging zu erleichtern und sicherzustellen, dass Ihr System sich anmutig von Fehlern erholen kann. Gehen Sie also voran, implementieren Sie diese Muster, und mögen Ihre Kafka-Topics immer fehlerbewusst sein!
"Die Kunst des Programmierens ist die Kunst, Komplexität zu organisieren, die Vielzahl zu beherrschen und ihr bastardhaftes Chaos so effektiv wie möglich zu vermeiden." - Edsger W. Dijkstra
Jetzt, mit diesen Techniken bewaffnet, sind Sie bereit, selbst die komplexesten Fehlerszenarien in Ihren ereignisgesteuerten Systemen anzugehen. Viel Spaß beim Programmieren, und mögen Ihre Fehler immer kontextbewusst sein!