Zusammenfassung
Die Implementierung von idempotenten Konsumenten in Kafka ist entscheidend, um Datenkonsistenz zu gewährleisten und doppelte Verarbeitung zu vermeiden. Wir werden bewährte Praktiken, häufige Fallstricke und einige clevere Tricks erkunden, um Ihre Kafka-Konsumenten so idempotent wie eine mathematische Funktion zu machen.
Warum Idempotenz wichtig ist
Bevor wir ins Detail gehen, lassen Sie uns kurz rekapitulieren, warum wir uns überhaupt mit Idempotenz beschäftigen:
- Verhindert doppelte Verarbeitung von Nachrichten
- Gewährleistet Datenkonsistenz im gesamten System
- Sparen Sie sich nächtliche Debugging-Sitzungen und frustrierendes Haare raufen
- Macht Ihr System widerstandsfähiger gegen Ausfälle und Wiederholungen
Jetzt, da wir alle auf dem gleichen Stand sind, lassen Sie uns in die Details eintauchen!
Best Practices für die Implementierung von idempotenten Konsumenten
1. Verwenden Sie eindeutige Nachrichtenkennungen
Die erste Regel des Idempotent Consumer Clubs lautet: Verwenden Sie immer eindeutige Nachrichtenkennungen. (Die zweite Regel ist... nun, Sie verstehen schon.)
Die Implementierung ist einfach:
public class KafkaMessage {
private String id;
private String payload;
// ... andere Felder und Methoden
}
public class IdempotentConsumer {
private Set processedMessageIds = new HashSet<>();
public void consume(KafkaMessage message) {
if (processedMessageIds.add(message.getId())) {
// Nachricht verarbeiten
processMessage(message);
} else {
// Nachricht bereits verarbeitet, überspringen
log.info("Überspringe doppelte Nachricht: {}", message.getId());
}
}
}
Profi-Tipp: Verwenden Sie UUIDs oder eine Kombination aus Thema, Partition und Offset für Ihre Nachrichten-IDs. Es ist, als ob jede Nachricht ihr eigenes einzigartiges Schneeflockenmuster hätte!
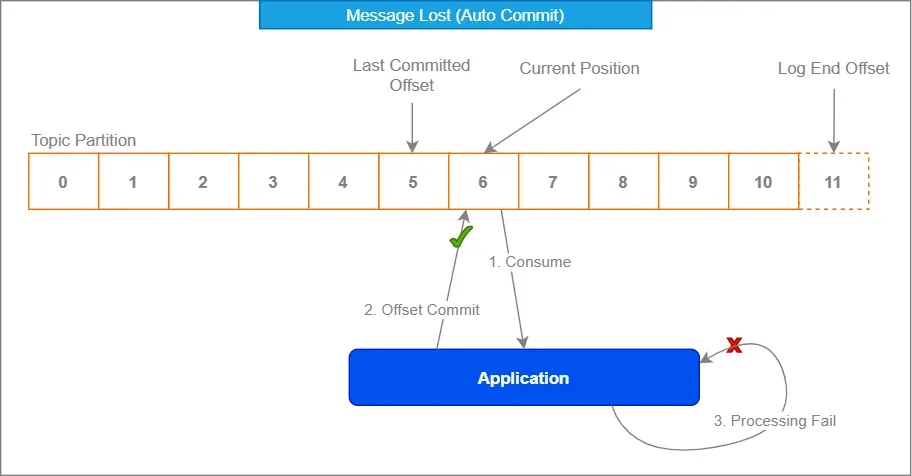
2. Nutzen Sie Kafkas Offset-Management
Kafkas integriertes Offset-Management ist Ihr Freund. Umarmen Sie es wie diesen seltsamen Onkel bei Familientreffen – es mag anfangs unangenehm erscheinen, aber es hat Ihren Rücken.
Properties props = new Properties();
props.put("enable.auto.commit", "false");
props.put("isolation.level", "read_committed");
KafkaConsumer consumer = new KafkaConsumer<>(props);
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
processRecord(record);
}
consumer.commitSync();
}
Indem Sie das automatische Commit deaktivieren und Offsets manuell nach der Verarbeitung festlegen, stellen Sie sicher, dass Nachrichten nur dann als konsumiert markiert werden, wenn Sie 100% sicher sind, dass sie korrekt behandelt wurden.
3. Implementieren Sie eine Deduplizierungsstrategie
Manchmal schleichen sich trotz unserer besten Bemühungen Duplikate wie heimliche Ninjas ein. Hier kommt eine solide Deduplizierungsstrategie ins Spiel.
Erwägen Sie die Verwendung eines verteilten Caches wie Redis, um verarbeitete Nachrichten-IDs zu speichern:
@Service
public class DuplicateChecker {
private final RedisTemplate redisTemplate;
public DuplicateChecker(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean isDuplicate(String messageId) {
return !redisTemplate.opsForValue().setIfAbsent(messageId, "processed", Duration.ofDays(1));
}
}
Dieser Ansatz ermöglicht es Ihnen, Duplikate über mehrere Konsumenteninstanzen hinweg und sogar nach Neustarts zu überprüfen. Es ist wie ein Türsteher für Ihre Nachrichten – "Wenn Ihre ID nicht auf der Liste steht, kommen Sie nicht rein!"
4. Verwenden Sie idempotente Operationen
Wann immer möglich, gestalten Sie Ihre Nachrichtenverarbeitungsoperationen so, dass sie von Natur aus idempotent sind. Das bedeutet, dass selbst wenn eine Nachricht mehrmals verarbeitet wird, das Endergebnis nicht beeinflusst wird.
Zum Beispiel, anstatt:
public void incrementCounter(String counterId) {
int currentValue = counterRepository.get(counterId);
counterRepository.set(counterId, currentValue + 1);
}
Erwägen Sie die Verwendung einer atomaren Operation:
public void incrementCounter(String counterId) {
counterRepository.increment(counterId);
}
Auf diese Weise bleibt das Endergebnis dasselbe, selbst wenn die Inkrementoperation mehrmals für dieselbe Nachricht aufgerufen wird.
Häufige Fallstricke und wie man sie vermeidet
Nachdem wir die Grundlagen behandelt haben, werfen wir einen Blick auf einige häufige Fallen, in die selbst erfahrene Entwickler tappen können:
1. Sich ausschließlich auf Kafkas "Exactly Once"-Semantik verlassen
Obwohl Kafka "Exactly Once"-Semantik bietet, ist es kein Allheilmittel. Es garantiert nur die einmalige Lieferung innerhalb des Kafka-Clusters, nicht die End-to-End-Verarbeitung in Ihrer Anwendung.
"Vertrauen, aber überprüfen" – Ronald Reagan (wahrscheinlich über Kafka-Nachrichten)
Implementieren Sie immer Ihre eigenen Idempotenzprüfungen zusätzlich zu Kafkas Garantien.
2. Transaktionsgrenzen ignorieren
Stellen Sie sicher, dass Ihre Nachrichtenverarbeitung und Offset-Commits Teil derselben Transaktion sind. Andernfalls könnten Sie in eine Situation geraten, in der Sie eine Nachricht verarbeitet, aber den Offset nicht festgelegt haben, was zu einer erneuten Verarbeitung beim Neustart des Konsumenten führt.
@Transactional
public void processMessage(ConsumerRecord record) {
// Nachricht verarbeiten
businessLogic.process(record.value());
// Nachricht manuell bestätigen
acknowledgment.acknowledge();
}
3. Datenbankbeschränkungen übersehen
Wenn Sie verarbeitete Daten in einer Datenbank speichern, nutzen Sie eindeutige Beschränkungen zu Ihrem Vorteil. Sie können als zusätzliche Schutzschicht gegen Duplikate dienen.
CREATE TABLE processed_messages (
message_id VARCHAR(255) PRIMARY KEY,
processed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Dann in Ihrem Java-Code:
try {
jdbcTemplate.update("INSERT INTO processed_messages (message_id) VALUES (?)", messageId);
// Nachricht verarbeiten
} catch (DuplicateKeyException e) {
// Nachricht bereits verarbeitet, überspringen
}
Fortgeschrittene Techniken für die Mutigen
Bereit, Ihr idempotentes Konsumentenspiel auf die nächste Stufe zu heben? Hier sind einige fortgeschrittene Techniken für die Mutigen:
1. Idempotenzschlüssel in Headern
Anstatt sich auf den Nachrichteninhalt für die Idempotenz zu verlassen, sollten Sie in Betracht ziehen, Kafka-Nachrichtenheader zu verwenden, um Idempotenzschlüssel zu speichern. Dies ermöglicht flexibleren Nachrichteninhalt bei gleichzeitiger Beibehaltung der Idempotenz.
// Producer
ProducerRecord record = new ProducerRecord<>("my-topic", "key", "value");
record.headers().add("idempotency-key", UUID.randomUUID().toString().getBytes());
producer.send(record);
// Consumer
ConsumerRecord record = // ... von Kafka empfangen
byte[] idempotencyKeyBytes = record.headers().lastHeader("idempotency-key").value();
String idempotencyKey = new String(idempotencyKeyBytes, StandardCharsets.UTF_8);
2. Zeitbasierte Deduplizierung
In einigen Szenarien möchten Sie möglicherweise eine zeitbasierte Deduplizierung implementieren. Dies ist nützlich, wenn Sie mit Ereignisströmen arbeiten, bei denen dasselbe Ereignis nach einer bestimmten Zeitspanne legitim wiederholt werden kann.
public class TimeBasedDuplicateChecker {
private final RedisTemplate redisTemplate;
private final Duration deduplicationWindow;
public TimeBasedDuplicateChecker(RedisTemplate redisTemplate, Duration deduplicationWindow) {
this.redisTemplate = redisTemplate;
this.deduplicationWindow = deduplicationWindow;
}
public boolean isDuplicate(String messageId) {
String key = "dedup:" + messageId;
Boolean isNew = redisTemplate.opsForValue().setIfAbsent(key, "processed", deduplicationWindow);
return isNew != null && !isNew;
}
}
3. Idempotente Aggregationen
Wenn Sie mit Aggregatoperationen arbeiten, sollten Sie idempotente Aggregationstechniken in Betracht ziehen. Anstatt beispielsweise eine laufende Summe zu speichern, speichern Sie einzelne Werte und berechnen die Summe bei Bedarf:
public class IdempotentAggregator {
private final Map values = new ConcurrentHashMap<>();
public void addValue(String key, double value) {
values.put(key, value);
}
public double getSum() {
return values.values().stream().mapToDouble(Double::doubleValue).sum();
}
}
Dieser Ansatz stellt sicher, dass selbst wenn eine Nachricht mehrmals verarbeitet wird, das endgültige Aggregationsergebnis nicht beeinflusst wird.
Zusammenfassung
Die Implementierung von idempotenten Konsumenten in Kafka mag wie eine entmutigende Aufgabe erscheinen, aber mit diesen Best Practices und Techniken werden Sie Duplikate im Handumdrehen wie ein Profi handhaben. Denken Sie daran, dass der Schlüssel darin besteht, immer das Unerwartete zu erwarten und Ihr System von Grund auf mit Idempotenz zu gestalten.
Hier ist eine kurze Checkliste, die Sie griffbereit halten sollten:
- Verwenden Sie eindeutige Nachrichtenkennungen
- Nutzen Sie Kafkas Offset-Management
- Implementieren Sie eine robuste Deduplizierungsstrategie
- Gestalten Sie nach Möglichkeit von Natur aus idempotente Operationen
- Seien Sie sich der häufigen Fallstricke bewusst und wissen Sie, wie man sie vermeidet
- Erwägen Sie fortgeschrittene Techniken für spezifische Anwendungsfälle
Indem Sie diese Richtlinien befolgen, verbessern Sie nicht nur die Zuverlässigkeit und Konsistenz Ihrer auf Kafka basierenden Systeme, sondern sparen sich auch unzählige Stunden des Debuggens und Kopfschmerzen. Und seien wir ehrlich, ist das nicht das, wonach wir alle streben?
Gehen Sie jetzt hinaus und erobern Sie diese doppelten Nachrichten! Ihr zukünftiges Ich (und Ihr Ops-Team) wird es Ihnen danken.
"In der Welt der Kafka-Konsumenten ist Idempotenz nicht nur ein Feature – es ist eine Superkraft." – Ein weiser Entwickler (wahrscheinlich)
Viel Spaß beim Programmieren, und mögen Ihre Konsumenten immer idempotent sein!