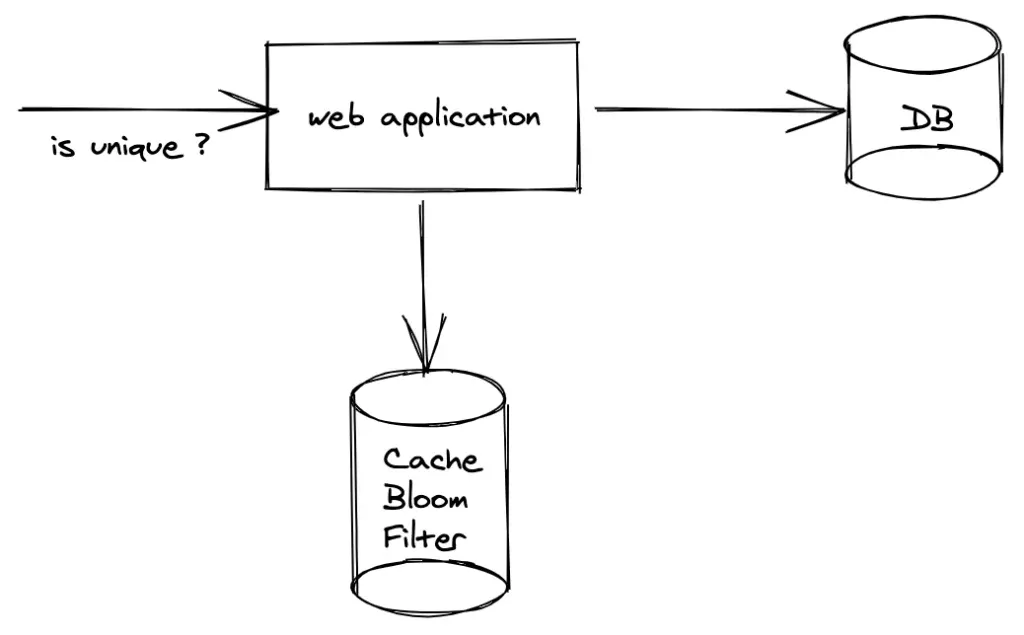
Lassen Sie uns aufschlüsseln, was ein Bloom-Filter eigentlich ist:
- Eine speichereffiziente probabilistische Datenstruktur
- Wird verwendet, um zu testen, ob ein Element Mitglied einer Menge ist
- Kann falsche Positive haben, aber niemals falsche Negative
- Perfekt, um unnötige Abfragen zu reduzieren
Einfacher ausgedrückt, es ist wie ein Türsteher für Ihre Datenbank. Es überprüft schnell, ob etwas möglicherweise im Club (Datenbank) ist, bevor es Sie tatsächlich hineinlässt, um sich umzusehen.
Betreten Sie Redis: Der schnelle Helfer
Warum also Redis? Weil es schnell ist. So schnell, dass man es kaum mitbekommt. Die Kombination von Bloom-Filtern mit Redis ist wie ein Raketenantrieb für Ihr ohnehin schon schnelles Rennauto.
Einrichten Ihres Redis Bloom-Filters
Zuallererst müssen Sie das RedisBloom-Modul installieren. Wenn Sie Docker verwenden, ist es so einfach wie:
docker run -p 6379:6379 redislabs/rebloom:latestNun, lassen Sie uns einen einfachen Bloom-Filter in Python mit der redis-py-Bibliothek implementieren:
import redis
from redisbloom.client import Client
# Verbindung zu Redis herstellen
rb = Client(host='localhost', port=6379)
# Einen Bloom-Filter erstellen
rb.bfCreate('myfilter', 0.01, 1000000)
# Einige Elemente hinzufügen
rb.bfAdd('myfilter', 'element1')
rb.bfAdd('myfilter', 'element2')
# Überprüfen, ob Elemente existieren
print(rb.bfExists('myfilter', 'element1')) # True
print(rb.bfExists('myfilter', 'element3')) # False
Die Magie hinter dem Vorhang
Wie hilft das tatsächlich, Datenbankabfragen zu reduzieren? Lassen Sie es uns aufschlüsseln:
- Bevor Sie Ihre Datenbank abfragen, überprüfen Sie den Bloom-Filter
- Wenn der Filter sagt, dass das Element nicht existiert, überspringen Sie die Datenbankabfrage vollständig
- Wenn der Filter sagt, dass es möglicherweise existiert, fahren Sie mit der Datenbankabfrage fort
Diese einfache Überprüfung kann die Anzahl unnötiger Abfragen drastisch reduzieren, insbesondere bei großen Datensätzen mit vielen Fehlversuchen.
Praxisbeispiel: Benutzer-Authentifizierung
Angenommen, Sie bauen ein Benutzer-Authentifizierungssystem. Anstatt die Datenbank bei jedem Anmeldeversuch mit einem nicht existierenden Benutzernamen abzufragen, können Sie einen Bloom-Filter verwenden, um ungültige Benutzernamen schnell abzulehnen:
def authenticate_user(username, password):
if not rb.bfExists('users', username):
return "Benutzer existiert nicht"
# Nur die Datenbank abfragen, wenn der Benutzername möglicherweise existiert
user = db.get_user(username)
if user and user.check_password(password):
return "Authentifizierung erfolgreich"
else:
return "Ungültige Anmeldedaten"
Fallstricke und Überlegungen
Bevor Sie Bloom-Filter überall einsetzen, beachten Sie folgende Punkte:
- Falsche Positive sind möglich, daher sollte Ihr Code Datenbankfehlversuche elegant handhaben
- Die Größe des Filters ist festgelegt, also schätzen Sie Ihre Datenmenge genau
- Das Hinzufügen von Elementen ist einseitig; Sie können keine Elemente aus einem Bloom-Filter entfernen
Leistungssteigerungen: Zeigen Sie mir die Zahlen!
Kommen wir zu den harten Fakten. In einem Testszenario mit 1 Million Benutzern und 10 Millionen Anmeldeversuchen (90% mit nicht existierenden Benutzernamen):
- Ohne Bloom-Filter: 10 Millionen Datenbankabfragen
- Mit Bloom-Filter: ~1,9 Millionen Datenbankabfragen (81% Reduktion!)
Das ist nicht nur ein Tropfen auf den heißen Stein; es ist eine Welle der Effizienz!
Überlegungen zur Skalierung
Wenn Ihre Anwendung wächst, sollten Sie über Folgendes nachdenken:
- Verteilte Bloom-Filter über mehrere Redis-Instanzen
- Periodischer Neuaufbau der Filter, um die Genauigkeit zu erhalten
- Überwachung der Rate falscher Positiver und Anpassung der Filterparameter
Fortgeschrittene Techniken: Zählende Bloom-Filter
Möchten Sie einen Schritt weiter gehen? Schauen Sie sich zählende Bloom-Filter an. Sie ermöglichen das Entfernen von Elementen und bieten ungefähre Zählabfragen. Hier ist ein kurzes Beispiel:
# Einen zählenden Bloom-Filter erstellen
rb.cfCreate('countingfilter', 1000000)
# Elemente hinzufügen und zählen
rb.cfAdd('countingfilter', 'element1')
rb.cfAdd('countingfilter', 'element1')
rb.cfCount('countingfilter', 'element1') # Gibt 2 zurück
Zusammenfassung
Die Implementierung von Bloom-Filtern in Redis ist wie das Geben einer Röntgenbrille an Ihre Datenbank. Sie kann durch den Lärm sehen und sich auf das Wesentliche konzentrieren. Durch die Reduzierung unnötiger Abfragen sparen Sie nicht nur Rechenleistung; Sie schaffen ein reibungsloseres, schnelleres Erlebnis für Ihre Benutzer.
Denken Sie daran, in der Welt der Hochleistungsanwendungen zählt jede Millisekunde. Warum also nicht Ihrer Datenbank eine Pause gönnen und Redis Bloom-Filter einen Teil der Arbeit übernehmen lassen?
Denkanstoß
"Die Kunst des Programmierens ist die Kunst, Komplexität zu organisieren." - Edsger W. Dijkstra
Und manchmal bedeutet das Organisieren von Komplexität zu wissen, wann man etwas nicht tun sollte. In diesem Fall, die Datenbank nicht unnötig abzufragen.
Gehen Sie nun hinaus und blühen Sie verantwortungsbewusst!